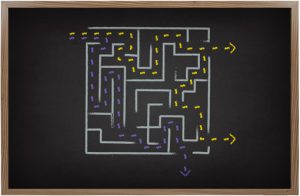
As many organisations are looking to leverage AI in learning, here we look at how to harness it effectively by putting guardrails in place in the form of ‘content pre-processing’.
It’s tempting to use LLMs within your LMS, in order to find new opportunities and efficiencies – with some additional steps, it’s possible to reduce the risk of errors and hallucinations.

Both formal training courses and informal knowledge-sharing generate valuable organisation-wide data that is not publicly accessible. However, they face challenges similar to those encountered on the broader internet: discovery efficiency and the effectiveness of educating users on specific topics.
Integrating large language models (LLMs) into a learning management system (LMS) offers exciting opportunities for leveraging this data. Below, we outline the potential benefits and explore the methods and challenges involved.
Key Value-Added Features
By utilising LLMs, organisations can develop advanced features that enhance learning experiences, such as:
- Aids for discovery and navigation: Making it easier to find relevant content within courses.
- Course-based assistance: Providing on-the-spot help while users consume material.
- Summaries and distillations: Offering concise overviews of course content for improved comprehension.
Functionality Overview
LLM-powered solutions within an LMS could enable the following:
- Natural language interaction: Questions and searches can be posed in plain English.
- Granular referencing: Answers are tied to specific course modules, e.g., modules X, Y, and Z of N.
- Real-time assistance: Support can be provided inline as content is consumed or via a separate interface.
However, these functionalities depend entirely on course-specific data, creating a need to balance this focus with the broader context provided by LLMs’ pre-trained internet-based knowledge.
Pre-Processing Course Content
To ensure accuracy and relevancy, course content must be pre-processed before being used by an LLM. The process involves:
- Exporting course language files: Relevant textual data needs to be taken from the content source in a way that preserves important structural elements so that information is still coherent to the LLM.
- Algorithmic refinement: Removing repetition, confusing metadata, and irrelevant details.
- Mark-up: Extra contextual structure needs to be added, which the LLM can be instructed to understand, enabling accurate navigational responses.
- API integration: Feeding the refined text files into an LLM alongside instructions that focus the chatbot on the learning materials.
It is important that most of the above elements can be achieved mainly through automation, with some human oversight, otherwise the costs, benefits and accuracy would be at risk.
This semi-automated approach requires significant technical expertise, including familiarity with data processing, SCORM standards, and API traffic management.
Challenges and Limitations
- Balancing context: LLMs must use their internet-based pre-training to provide broader context while prioritising course-specific data. Fine-tuning this balance remains complex and critical, particularly for sensitive topics such as regulatory or safety training.
- Minimising hypothesising: Ensuring the model avoids guessing when it does not fully understand a query is challenging but essential for accuracy and trustworthiness.
- Functional queries: LLMs often excel at creative or general-purpose tasks but struggle with highly functional queries, such as listing all modules mentioning a specific keyword. While iterative questioning can improve results, the models do not learn from such interactions, as most LLMs maintain session-specific context without permanent learning.
- Dynamic error handling: Unlike some emerging models, such as X/Twitter’s GROK, which claim to “learn on the job,” many LLMs require manual oversight to address errors and refine responses.
Practical Considerations
Here at Day One Technologies, we’ve been creating solutions to minimise the risk of LLMs going “off course.” By implementing constraints and pre-processing filters, we ensure LLM outputs remain reliable and focused on the training materials. For example, content filters act as a preparatory layer, much like how web templates load before dynamic elements for speed and efficiency.
Conclusion
It is feasible to develop a course content-driven chatbot that is helpful and reasonably reliable. However, achieving this requires robust technical preparation and ongoing refinement. While LLMs offer significant potential for enhancing LMS capabilities, they are not without limitations, including accuracy issues and evolving API constraints.
Organisations must carefully assess the risks, particularly when the target audience requires a high degree of precision, such as in regulated industries. With thoughtful implementation, LLMs can be a valuable tool for improving content discovery and learning outcomes.
Further Reading
- SCORM Standards and LMS Integration
Learn about SCORM compliance: ADL SCORM Overview - Large Language Models in Education
Explore the potential of AI in training and education: Stanford HAI – LLMs in Education - AI Safety and Ethical Risks
Understand the challenges of AI errors in sensitive areas: Oxford AI Safety Research