Here we provide an elearning development checklist to help L&D teams create a template for future-proof training content, as well as making its maintenance part of your project plan.
This kind of planning is relevant whether you are creating content in-house or working with an external elearning company, and helps to reduce your training costs considerably over time.

When planning an elearning content development project, making your training future-proof is generally low on everyone’s list of priorities – if it makes it on there at all.
In dynamic industries or competitive markets, change is constant and you’ll often find that content that was once great, feels less and less relevant and helpful. Learners disengage and uptake falls, but you don’t want the expense, in terms of both time and budget, of bringing it up to date with a big refresh project.
It doesn’t need to be like this – here we look at how making future-proof elearning content a key part of the development process can help to keep relevance and engagement high, and ongoing costs low. We’ll summarise with a future-proof content checklist at the end.
Let’s talk about Maintenance
I don’t see many people on Twitter or LinkedIn talking about elearning maintenance. Funny that. It’s not sexy. It’s a shame because early and continued attention to this issue can save a fortune.
To be clear, I am principally talking about maintenance of elearning content.
Your elearning content should really be maintained because systems, processes and legislation / compliance inevitably change, and often quickly these days. Your training has to update as well or it won’t be effective.
Certainly maintenance is usually something that comes up at the beginning of a new project, and is dealt with at least on the surface in a serious manner. More often than not though the deal is essentially done before maintenance in practice is fleshed out and by then the client has little choice but to pick from options dictated by the supplier(s).
Even if the project is in-house it will more than likely rely on software packages which also limit or enable your maintenance options – so knowing these pros and cons in advance of agreeing the solution would be highly useful.
What very often happens with a medium to large elearning project is that things in the business change pretty shortly afterwards (or even during the project). People move on. Priorities adjust. Then the required maintenance becomes too expensive or resource consuming. Or complacency drifts in.
Then the elearning content gets into a state where it is so patchy in accuracy that trainers don’t want to use it and the project dies a death usually to be followed at some point be a brand new (and rather expensive) project to replace what was there.
This can be seen as part of the natural business cycle where the technology and approach of the original content is outmoded and a good wholesale re-think and regeneration of the training is healthy especially when linked to major business transformation. A lot of the time however the problems with costs and degradation occur well within the natural lifetime of the training project with a lot of negative cost implications.
So from our experiences I am going to discuss a few points which I think are important with regards to Maintenance, and tap into some concepts which are not particularly technical and very useful for the client to understand.
How Expert do you want to be?
It is useful to get a handle on what are the in-house skills you will have available for maintenance, and how far they go up the expertise ladder. From my experience an update will (typically) break down into a basket of jobs like this:
- 80% are not complex (words and options changes and reworks)
- 15% require significant expertise (animation, simulation, structural)
- 5% are difficult (scripting, code & large volume).
If none of your staff SME providers have professional e-learning experience yet have tech ability and some training in working e-learning packages then 50-80% of it could be handled in-house, but the final 20% (which tends to be critical) will need a higher skilled resource. So you will either have to bring this in house or get someone outside to do it perhaps through an ongoing maintenance agreement.
Winging it will not work, and you need to consider the business case for carrying technical professional e-learning resources with all the pitfalls and overheads that can bring. Many businesses, especially larger ones, do maintain significant in-house e-learning development teams and even their own author-ware, and often look to create income stream from these endeavours.
If you are not a large business though it seems to be a distraction to technically focus on something which is probably nothing to do with what the business is there to do or sell.
So a useful exercise is to break down all the likely types of changes you might want to make to the content based as much on experience as you can, and then work through what you might want to keep in-house based on the skills you have. This exercise can throw up a lot of questions and new thoughts – which you can then discuss with your (potential) provider(s).
I will now provide a very basic maintenance example which brings to life some important points.
Example
Suppose you have a significant body of e-learning which covers several important business products, how you build them, sell them, support them. It covers the staff procedures, work-processes, guidelines around these. You get the picture.
A major business change has occurred and in 6 months this change will be rolled out for real.
The training needs to be amended fast to allow change training to occur in time for reality hitting with customer needs to be serviced. So the e-learning will have to change.
One small part of the change is that a product name is being changed – The ‘Blue Fin’ is now the ‘Green Fin’
What you want here is the ability to identify quickly where the original product name (Blue Fin) exists in the content base. This ability is much more powerful than enabling you to do some word replaces, it will allow you to, through a basket of searches, form a foot print of content which needs to be re-assessed. It is unlikely that your SME’s will just know from memory everywhere effected by change and this facility acts as your radar.
This is a ‘spearing’ technique. A bunch of word tokens can be used as a first pass to gain visibility of the jobs that need doing. A lot of the work will certainly not be simply word replaces, but the searching ability will at least act as a radar and will simplify a lot of the more basic jobs as well. It is certainly far better than trying to work from collective memory.
So in our example we ideally want to be able to search the content based for all instance of ‘Blue Fin’, review them in context to check they are valid to replace (and not some word fluke), then press a button to update. Later down the update chain we would then want to remember our list of changes to check all the impacts and what follow on changes are requisite, which may be none or many depending on the essence of the change, but the important thing is we are taken efficiently and quickly into the heart of the job.
Open-ness
To have this ability we need the authoring files (source) and published files to be as open* as possible. What do I mean by this? Well it means that the files are in a format that can be opened and read by humans or other software such as text files, regular HTML files and XML files. IF that is so then there are hosts of tools which are cheap or free which enable content update processed as I describe.
Even if you have no access to the authoring files and just have say published SCORM** files you will then be able to perform searches to identify precisely a lot of the changes you want and document them which should save money and be more efficient. You could even do updates of to the SCORM files although this is not a sustainable approach and more of a last resort (can have problematic consequences).
*Important – this is nothing to do with the concept of open source software. The open-ness of your content is nothing to do with software ownership and property rights. It means mean how much the content is open to use by humans or other suppliers and vendors.
**The SCORM files constitute the actual, published, e-learning material or you could think of as the e-learning end product. They are usually (but not always) different to source files used by software used to facilitate easy user friendly authoring.
However your content is being produced, even if it’s completely in-house, you really need to consider the above. The more open your content documents (source and output) the better, and more room for manoeuvre you will have in the future to update your content.
So let’s look at the big 3 content authoring products as way of an example. Storyline, Captivate & Lectora. Actually, all have some shortcomings in this department – here is the situation.
Lectora is the best of the 3 having its authoring files in XML and its HTML5 output in conventional XHTML format. It’s a little tricky to understand its structures, and how it handles text is irregular. We can easily search for text and meta-data and do automatic updating up to a point.
Captivate is a little more demanding in that the authoring files are compressed and in quite difficult proprietary formats. Its output is in an awkward HTML script format. So it is still possible to search the output and work with the authoring files, but not so much.
Storyline compresses the authoring files, but within this they are in a reasonable XML layout to facilitate search and replace. The HTML5 output is however vector based non-standard HTML and very tricky to work with.
All 3 packages are crying out to have some management tools to directly facilitate content management and maintenance or they could at least offer a decent API to facilitate this (an API in this context is jargon for the vendor offering a handle to people like us to more easily see into the source files and manipulate them).
Now let’s get back to our example
If our content is open enough, in a good scenario, and armed with the right software we can replace all the occurrences of ‘Blue Fin’ with ‘Green Fin’ in on swoop.
We, for example, use PowerGREP which is not freeware but very cheap and probably one of the most useful pieces of software we use. You can look for instances of phrases, look at the context and review the potential changes. Produce reports to assess. Then press the button to update if that is appropriate.
Being able to review the context of search results inevitable throws us some other subtle changes that need to be made e.g. in this case it might just be references to the blue as a colour, the use of blue or usage of the term in images.
It will depend on all sorts of factors, but the ease of executing this example in its entirety will be heavily dependent on the open-ness of the content and your abilities to manipulate it.
If you are considering a solution from a supplier, it could be worth asking them about this scenario.
Content Isolation
The example we are running with also brings into sight another structural issue with your content. We have always believed it is best for content to have structure and information as separated as possible.
At a simple level, this should mean there should be a hierarchy to the content files or at least segments of those files which follow a format
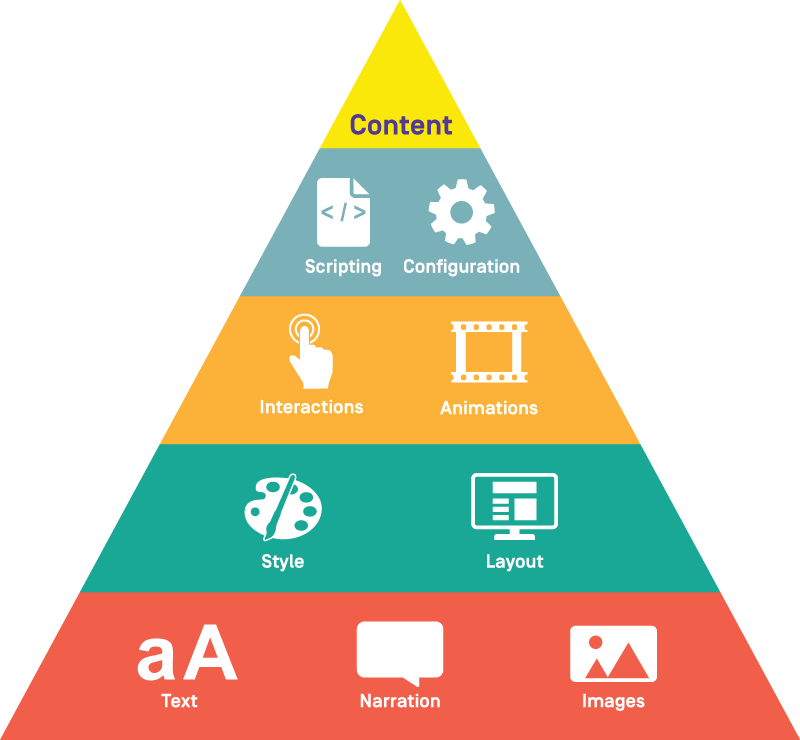
So it is possible to set somebody up to edit one of these categories without risk of accidently breaking something they didn’t mean to.
This means for example, if ‘Blue fin’ could refer to two (CSS) style items ‘Blue’ and ‘Fin…..’ within some script and there is a risk of bulk changes ruining styling in some of the content. Worse can of course happen; there is a danger to large blanket changes (which can involve language issues of course).
Content should be structured so you can let someone non-technical loose on the text aspect of the content for example, without worry of them breaking all the interactions subtly in a remote part of the content. You may only discover these errors months later when there is no way to back the change out. This is a classic problem that always occurs and can be costly. Be clear on the limitations of isolation within your solution and at least flag-up where you might get problems.
Agreeing standards and naming conventions at an early stage will always help you isolate different sorts of content.
Structure Sharing
There is another fundamental concept which is important for large bodies of content – that of ‘minimum redundancy’.
It’s actually quite a simple thing. Whenever something is the same in more than one place, these ‘repetitions’ should be shared from the same place. This applies to text, interaction types, graphics, style and structure.
So a repeated piece of text should if possible exist in the content in one file, and all the places where it is used should simply point to this.
Similarly if there was a style template, then the template wouldn’t just be copied in every time it is used, it would be referenced.
If the content is organised this way then it avoids the risk of ‘drift’ in content where some is updated one way, other content left or updated in another way. It makes maintenance easier and enforces content integrity.
All the authoring tools around are lacking when addressing this issue, though some allow some degree of structure sharing. Powerpoint and Storyline allow ‘slide masters’ which govern the look and feel of a content page but not much more.
For our example, the more structure sharing there is, the less instances of ‘Blue Fin’ are going to come up on any search sweep. And this usually translates to less work.
Going back to Open-ness again
Having well-structured and isolated content is a huge bonus, but it’s the overall open-ness which is the real story here.
The more your content base is open, well-structured and isolated; the easier and cheaper the maintenance will be. It needs to be cheap and easy enough for it to actually happen otherwise the content will quickly wither.
There are also knock-on advantages to having content as open as possible. You can transform your content into a searchable knowledge base or drive discovery using search tools as well.
Open content will also allow your LMS to enable feedback features so errors and glitches can be easily reported and matched automatically to the exact content the user had in front of them at that time – which is important.
Vendors and suppliers are traditionally not very good when it comes to content open-ness. They want you to renew their licenses and/or support agreements and open content shifts the power back to the client. But this where the power should lie for effective and log lasting training to eveolve.
Future-Proof eLearning Checklist
Here are a list of maintenance-related issues we think everyone should be aware of when planning a major project.
- How open is the solution? Ask a vendor to list the non-vendor tools that can be used to work with their content.
- What are the risks of non-technical staff working on wording changes? Clients should not be expected to be technical experts but can be enabled to make at least basic changes.
- Structural sharing easy? How well does a proposed solution deal with repetition and templating, and avoid the problems of content drift and piece-meal updating?
- Maintenance possible in-house if desired? Be realistic about what in-house skills you will have to do different levels of technical maintenance.
- Update procedures clear? How will updates work in practice? You don’t want changes to just suddenly appear as updates are done. Version control is advisable.
You need to be as much in control over the content as possible in a major elearning project. But also not exposed by any lack of resources and / or skills to service aspects of effective maintenance. There is a balance to strike here and it’s worth really thinking about it before you dive in.
Make sure you have future-proof elearning – down the line you’ll be glad you thought about maintenance in advance.
Are you planning an elearning content development project?
Do contact us for an informal discussion about your training needs.